

For the past several years I’ve been conducting a One-Name Study on the FIRTHs (and FRITHs, since the two are so frequently mis-transcribed) of northern England: primarily Cheshire, Derbyshire, Lancashire, Lincolnshire and Yorkshire. I think I’ve got the 19th century fairly well covered (35,000 individuals, 10,000 families and still WIP), I’m not really interested in the 1900s, so my future goal is to push further back into the 18th century.
In collecting and collating this volume of data, I’ve devised what might grandiloquently be termed a simple research methodology. The purpose of these notes is to share with other ONS researchers my conventions for doing things, on the off-chance that somebody may find it useful. I’m certainly not insisting that you do things my way; rather I’m offering ideas on approaches that you just might not have considered.
I’ll make eleven recommendations:
Start with a fairly clear idea of what you’d like to achieve. Luckily for me, FIRTH is a relatively uncommon surname – especially outside the north of England – so the aim of documenting the majority of 19th century FIRTH families didn’t seem too unrealistic. In the event, this has proved true (albeit at the cost of committing several hours a day, seven days a week, to the task). However, I must quickly go on to clarify that by ‘documenting’ I mean only capturing the very basics – births, marriages, deaths and all census records – for my subjects. In essence, my ONS aims for breadth rather than depth: if you like, a puddle not a pothole. My initial hope, happily validated by subsequent feedback, was that folk researching a FIRTH ancestor would be pleased if their findings were confirmed by a third party, and perhaps encouraged to delve much deeper than I am minded to, not to mention sharing their findings for the benefit of others.
A further consideration, for me, was cost (well, would you spend a million pounds on BMD certificates for 35,000 individuals at £28 a head?). All of my data is gathered from the several excellent free websites, or from Ancestry UK (and of course the downside of no hardcopy evidence is the certainty that errors will creep in; it happens). The only other ONS outlay, over and above an internet connection, is software to record the data.
A purpose-built tool for capturing family relationships is going to lie at the very heart of your research, so invest in something that’s sufficiently powerful and trustworthy for the purpose. I run Family Historian, an extremely impressive genealogy program, on my PC. Its virtues include enormous flexibility, 100% GEDCOM conformance, an active development schedule, and outstanding support both from the developers and from its user group (I've put a handful of ONS-specific Queries in the User Group Knowledge Base). Of course there are other products on the market; maybe they’re slightly less impressive...? Whatever: in the overall scale of your time and effort, the software costs are insignificant.
What you should not do, in my totally subjective opinion, is use web-based family history creation tools. Your abilities to own your own data, to record exactly what you want, to edit it to reflect whatever new information appears, and – critically – to export it as a GEDCOM-conformant file, are all likely to be substantially inferior to what you can achieve when your database resides on your PC. (Sorry, Mac users, your options are probably nearly as poor as my experience).
While we’re focussed on the underlying hardware/software, I can’t over-emphasise the value of working with a wide-screen (22+ inch) monitor. The ability to display both your source information and your genealogy database side by side is a benefit almost impossible to over-estimate. Trust me on this.
Right, we’ve covered the goals and the technology. Now we come to the issues of exactly what to record, and specifically what compromises it’s sensible to make. Here, I have three words of advice: normalise, normalise, normalise. By that I mean: iron out small differences in your data into one standard form that you use throughout your database. In my ONS, I find myself constantly asking “could individual X be the same as individual Y?”. Making this comparison is easier – no, less difficult – if you’ve removed minor discrepancies. Bear in mind that, at least until the 1870s, large parts of the population couldn’t read or write, and that therefore their personal details were recorded -- unchecked -- by some cleric or clerk based on what they heard. Also, the focus on exactly when an event occurred was dependent almost totally on memory rather than on documentation, so it’s hardly surprising that multiple variations of the same name or date or place are commonplace. What I’m saying is: establish standard versions of recurring data, and use that standard version rather than the dubiously-specific version you encounter in some historical record.
We’ll start with surnames. In my own database, FIRTH and FRITH are clearly distinct, and yet need considerable care to overcome multitudinous recording and transcription errors. That’s not really what I’m talking about: it’s the names of the people that FIRTHs marry. While some surnames seem to come across reliably – ATKINSON, BACKHOUSE and CHARLESWORTH for example – others are much more problematic. Surnames like AINSWORTH, BATTYE and CLARK can appear in two, three or more manifestations, with no obvious rationale. My advice is: ignore the differences, and focus on one version which you record consistently for all appropriate entries. Which version to use? That’s a question you can’t really answer until you’ve recorded a few thousand records verbatim. But at some point, once you’ve established a reasonable sample of surnames which relate to your primary focus, it’s worthwhile conducting a cleanup exercise whereby you review the accumulation of secondary surnames, and normalise minor differences into one standard version (for the purposes of matching records). As with all of this information, your ONS is presenting data in a form which aims to maximise its value to other researchers. Anybody using the data as a starting point is of course more than welcome to undo any little normalisations that they disagree with.
Normalise your given names, for exactly the same reason: you want to spot that individual X is probably the same as individual Y. Therefore, avoid gratuitous variations (Anne and Annie become Ann, Charlie and Charley are both recorded as Charles) and contractions (Thos and Tom become Thomas, Willie and Wm are recorded as William). For names like Alan, Allan and Allen, choose one and stick with it, as also for Betty, Millie, Nelly, Susannah and many others. Remember that Jessie and Frances are female, Jesse and Francis are male. And so on; use your common sense.
It’s no great surprise that people’s idea of the date they were born was often unreliable. If I find a Civil Registration entry then I use the format “Q3 1850”, and of course if I find a christening record with the actual DOB included, that’s wonderful. Most of the time though, I have to estimate dates of birth from census entries. Most censuses were taken in March or April. So, for example, if somebody is shown as age 15 in 1871, then there’s a 33% probability they were born in Q1 1856 but a 67% probability they were born in Q2–Q4 1855. Accordingly, I’d enter “c.1855” for their DOB.
If I have a source for a BMD event, I record it using what’s commonly known as Method 2; all births are recorded against either my Parish Births and Christenings source or my Registered Births source; the same scheme applies to marriages and to deaths (this is in contrast to my Census events, which I record using Method 1 – see Recommendation 8). Here’s the end of my Sources window:

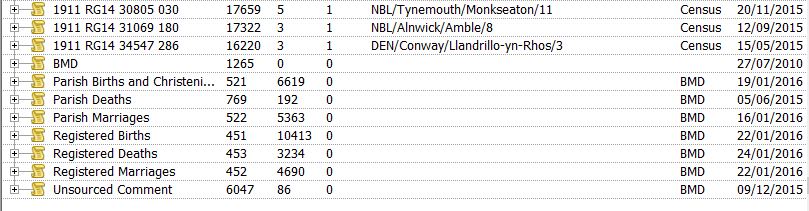
An Unsourced Comment is useful when somebody emails me with additional data on their family which I have to take on trust; it’s a simple way of recording the date and sender of the email.
There’s one additional field that I employ with Marriages: the Note field. This is what a Parish Marriage and a Registered Marriage look like:
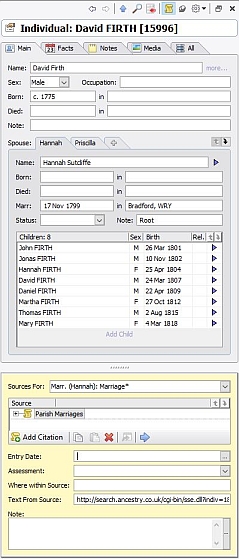
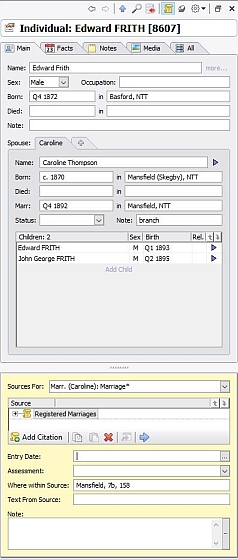
The Note field can take one of three values: Root (this is the starting point for the family below, as far back as I currently go), branch (this is a marriage (below a Root) where the husband, and any children, are FIRTHs), and stump (this is a marriage (below a Root) where the husband, and any children, are not FIRTHs; I lose interest in this family from now on). When an unmarried female FIRTH bears a child, I give her a male partner of Unrecorded // (See Recommendation 10), and label the liaison as either Root or branch, as appropriate. Here’s a section of my Families window; I’ve included the Note field in the display, and indeed in the display sort criteria, so that all the Root marriages come together in date order:

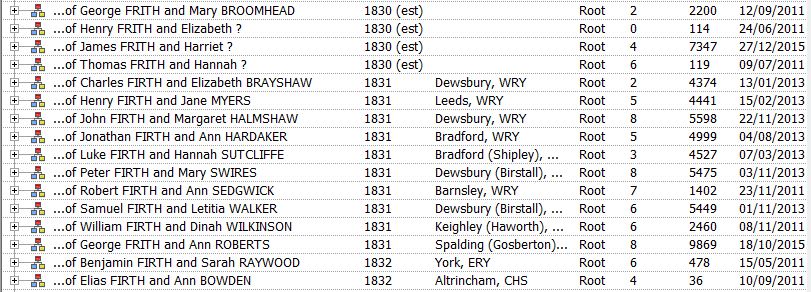
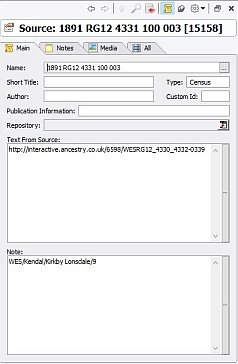
You’ll also see that I (mis)use the Text from Source field for Parish BMDs; I use it to hold the URL of the record from which I took the data. I don’t expect such a URL will be valid for very long, but at least it specifies the website where I found the record.
I don’t use Nick Walker’s excellent Ancestral Sources tool; it’s overkill for my purpose, because I record so little information.
Right: now let’s talk about Places. Yet again, there’s no consistency in the detail of information available: I’ve encountered everything from a street name, a hamlet, town... all the way up to just the name of a country. For my purpose – matching individual X with individual Y – it’s enormously helpful if locations which are geographically close are also close alphabetically. Accordingly. I use the formats “place, county” (for English locations, the overwhelming majority) and “place, county, country” (for Wales, Scotland and the rest of the world). I spell out country names in full, I use three-letter Chapman Codes for county names, and my place names are based on registration districts and the civil parishes and townships within them. Let me give a couple of examples. Belper (Crich), DBY refers to the parish of Crich in Derbyshire, Belper, DBY refers to an unknown parish in, or to the township itself of, Belper and , DBY refers to an unknown area of Derbyshire. The “Index of Place Names” downloadable from www.ukbmd.org.uk/genuki/reg is an invaluable aid to creating Place records. Incidentally, Mike Tate’s Map Life Facts plugin does a pretty good job of geo-coding place names in this format.
Of course, life is never simple. Some places alter their names, pair up, split apart; some float between registration districts over the years. I ignore such changes, just opting for the name and district which applied for the majority of the 19th century; this works well enough for my purposes.
For double-barrelled names I use -i- for in, -o- for on, over and upon, -u- for under, and so on. Thus for example:
Doncaster (Thorpe-i-Balne), WRY,
Newcastle-o-Tyne, NBL and
Newcastle-u-Lyme, STS.
And in place of and, cum, with and the like, I use a simple semicolon-separated list:
Clitheroe (Aighton; Chaigley; Bailey), LAN,
Birkenhead (Poulton; Seacombe), CHS and
Macclesfield (Poynton; Worth), CHS.
Here’s a section of my Places window:

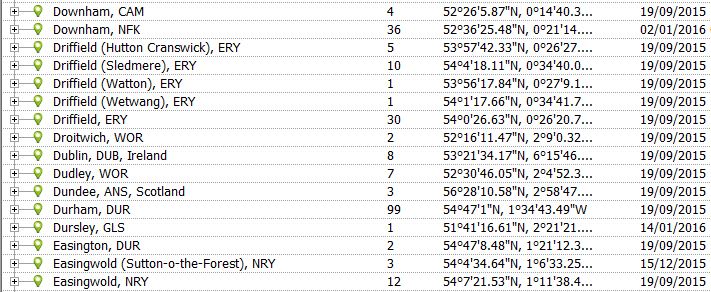
At last, we get to talk about Census Source records, certainly the most complex of the record types that I use. I’ve got about 18,000 Census Sources, most of them cited multiple times using what’s commonly known as Method 1. Each Census Source identifies a single page of census data (two pages in 1841), and is named to reflect the General Records Office reference number for the page. The formats I use are:
1841 HO107 PPPP bbb fff
1851 HO107 PPPP fff ppp
1861 RG09 PPPP fff ppp
1871 RG10 PPPP fff ppp
1881 RG11 PPPP fff ppp
1891 RG12 PPPP fff ppp
1901 RG13 PPPP fff ppp
1911 RG14 PPPPP sss
where PPPP is the four-digit Piece number, bbb is the three-digit Book number, fff is the three-digit Folio number (for 1841 I use the number top-right of the second page), ppp is the three-digit Page number and, from 1911, PPPPP is the five-digit Piece number and sss is the three-digit Schedule number. Values that are shorter than the specified size are padded out with leading zeroes. The (very few) instances of values which are longer than the specified size are left unchanged.
Here’s how it all works:
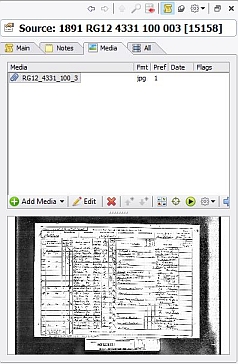
Here are the details for a typical Census Source record:
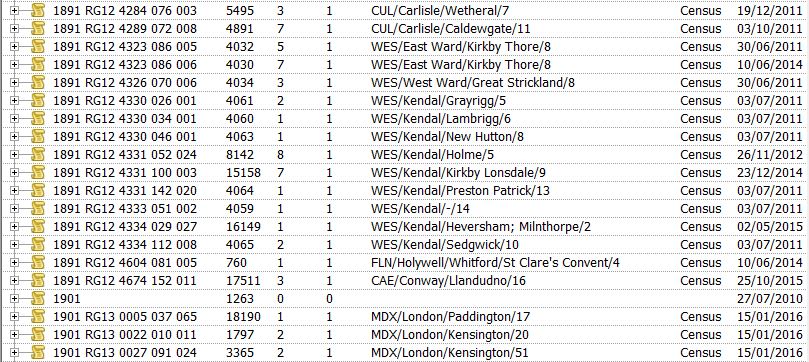
And here is the census part of the Sources window, with the Note field column renamed as Registration District:

I don’t put a lot of effort into completing Address fields: they’re frequently missing, or illegible, or what looks like the name of a single property. In the cases where I can decipher the Address, I use one of two generic forms: one is High * to cover High Street, High Tor, etc, or School * for School Lane, School Road and so on. The other form is * Farm, * Inn, * Prison, * Workhouse and similar, for establishments of that type.
In addition to the thousands of real folk that I try to document, there are three invented male names that I use as necessary:
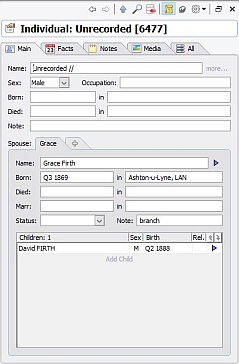
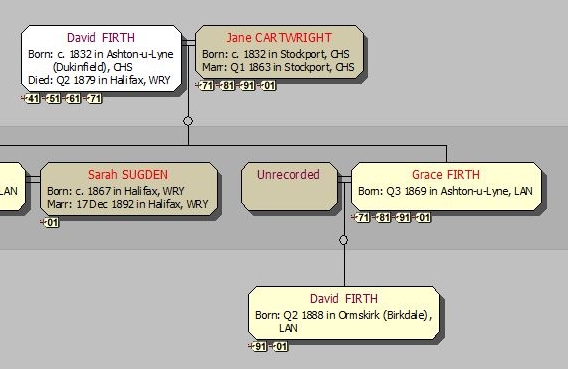
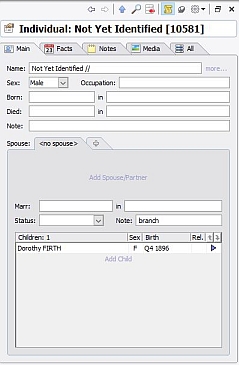
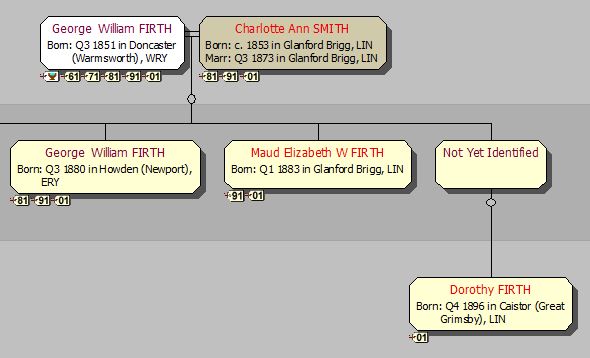
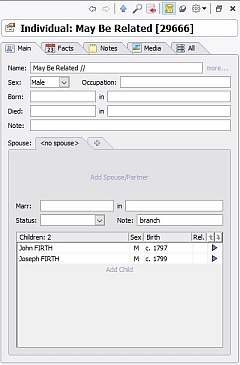
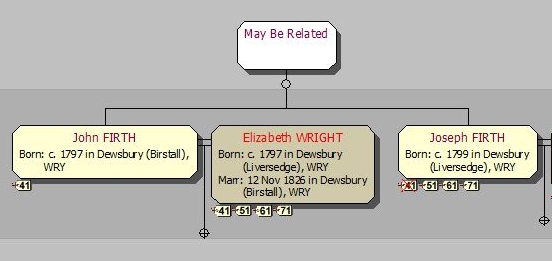
All three of these are created individually as and when required. Their ‘marriage’ is of type branch – see Recommendation 6.
I try to research my FIRTH families with an open mind, generally starting from an individual’s appearance in a census entry and then attempting to work backwards and forwards to reconstruct their surrounding family. This doesn’t always work: some folk seem to surface once or twice, then disappear without trace. When I’m completely stuck, I’ll try looking at Family Trees on Ancestry UK, just in case somebody else has cracked the problem. Be cautious: this very rarely helps. In those cases where I do find an applicable record, it’s scarily rare to discover any supportive data; generally, the only source turns out to be another unsourced Ancestry tree. Treating that as reliable data helps nobody: if you can’t find a reasonably trustworthy source for an event, you shouldn't record it. Beware verisimilitude; when searching for the truth, scepticism should always win out over hope.
There you are: we're done. I hope you found something of value, or at least nothing that was obvious rubbish. Either way, you're welcome to contact me using roger@firthworks.com. Good luck with your research!
Modified 19 Aug 2016